📝 I will be back in Australia before the end of April 2024 and will be looking for a new position within my skillset (latest CV available on request) so please let me know if you know of any roles coming up. I will be based 1 hour north of Sydney.
This post outlines my findings from my investigation of Azure AI Search. The reason I am writing this post is to expand my knowledge of Azure AI by producing a working proof of concept that I will make available in a GitHub repository.
Table of Contents
- Table of Contents
- The Aim of this Post
- What is Azure AI Search?
- Why use Azure AI Search?
- Code Overview
- Code Walk Through
- Change Detection
- Search Security
- Why is Azure AI Search so good?
- Issues I encountered
- Useful Links and Documentation I Used
The Aim of this Post
I would like to achieve the following outcomes after completing my investigation of Azure AI Search:
- Understand Azure AI Search at a substantial level - enough to send a search request and get a usable response. Once I understand the basics I will try to do more focussed and detailed posts about other Azure AI technologies.
- Write a small proof of concept application that ties everything together. This will include:
- The Terraform to deploy the main resources to Azure
- The Postman Collection that will take care of deploying the resources internal to the Azure AI Search resource (Terraform doesn’t seem to support these yet).
- A website front end (.NET MVC) to consume the search REST API response and display it in a useful way
- Make all the code available for others to fork and use.
What is Azure AI Search?
Azure AI Search, formerly recognized as “Azure Cognitive Search,” delivers secure and scalable information retrieval for user-owned content in both traditional and conversational search applications.
Fundamental to applications displaying text and vectors, information retrieval plays a crucial role. This encompasses various scenarios such as catalog or document searches, data exploration, and the emerging trend of chat-style copilot applications utilizing proprietary grounding data. When establishing a search service, you leverage the following capabilities:
- A search engine supporting vector, full text, and hybrid searches across a search index.
- Comprehensive indexing featuring integrated data chunking and vectorization (in preview), lexical analysis for text, and the option for AI enrichment to extract and transform content.
- Robust query syntax enabling vector queries, text searches, hybrid queries, fuzzy searches, autocomplete, geo-search, and more.
- Utilization of Azure’s scale, security, and extensive reach.
- Seamless integration with Azure at the data layer, machine learning layer, Azure AI services, and Azure OpenAI.
Looking at Azure AI Search from an architectural perspective, a search service functions as an intermediary positioned between external data stores housing your un-indexed data and the client app responsible for sending query requests to a search index and managing the subsequent response.

Within your client app, the search experience is crafted using APIs provided by Azure AI Search. This includes various functionalities such as relevance tuning, semantic ranking, autocomplete, synonym matching, fuzzy matching, pattern matching, filtering, and sorting.
Azure AI Search seamlessly integrates across the Azure platform by incorporating indexers, which automate data ingestion / retrieval from Azure data sources. Additionally, it leverages skillsets that integrate consumable AI from Azure AI services, encompassing capabilities like image and natural language processing. Furthermore, Azure AI Search supports custom AI, allowing you to create or encapsulate it within Azure Machine Learning or wrap it inside Azure Functions.
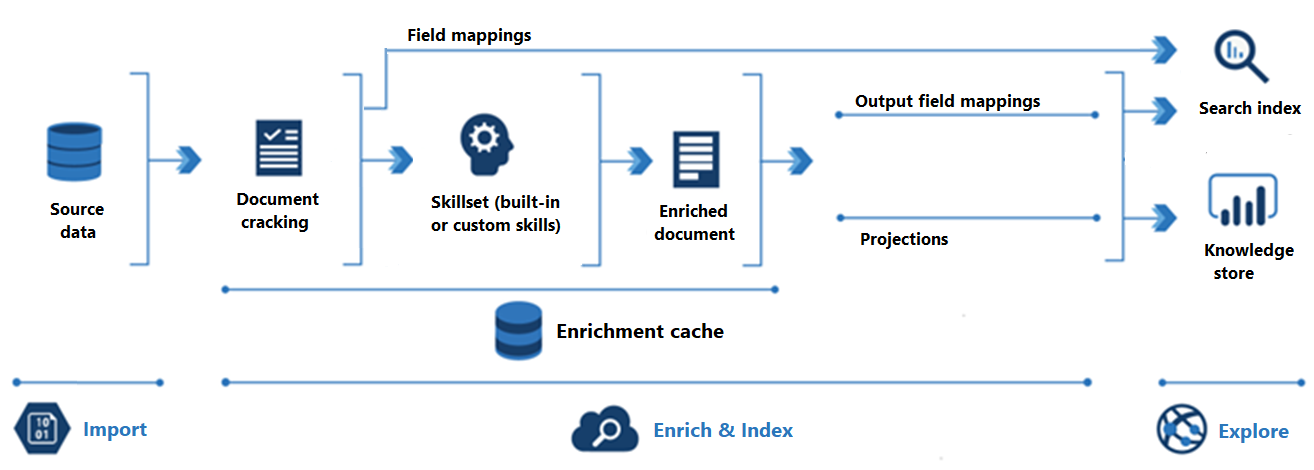
What is Document Cracking?
Document cracking is the process of opening files and extracting content. Text-based content can be extracted from files on a service, rows in a table, or items in container or collection. If you add a skillset and image skills, document cracking can also extract images and queue them for image processing.
What are Azure AI Search Skillsets
A skillset is a reusable resource in Azure AI Search that’s attached to an indexer. It contains one or more skills that call built-in AI or external custom processing over documents retrieved from an external data source.
Why use Azure AI Search?
Azure AI Search proves advantageous for various application scenarios, including:
-
Traditional Full Text and Next-Generation Vector Similarity Search: Employ Azure AI Search for traditional full text searches and advanced vector similarity searches. Empower your generative AI applications with information retrieval capabilities that utilize both keyword and similarity search modalities, ensuring the retrieval of the most relevant results.
-
Consolidation of Heterogeneous Content: Create a user-defined search index comprising vectors and text, allowing you to consolidate diverse content. With Azure AI Search, you have ownership and control over what is searchable.
-
Integration of Data Chunking and Vectorization: Seamlessly integrate data chunking and vectorization to enhance generative AI and RAG (Retrieval-Augmented Generation) applications.
-
Granular Access Control: Implement granular access control at the document level, providing heightened security.
-
Offloading Indexing and Query Workloads: Shift indexing and query workloads to a dedicated search service, optimizing performance.
-
Easy Implementation of Search-Related Features: Leverage Azure AI Search for the effortless implementation of search-related features, including relevance tuning, faceted navigation, filters (including geo-spatial search), synonym mapping, and autocomplete.
-
Transformation of Large Files: Transform large undifferentiated text, image files, or application files stored in Azure Blob Storage or Azure Cosmos DB into searchable chunks during indexing. Cognitive skills add external processing from Azure AI to achieve this.
-
Linguistic or Custom Text Analysis: Add linguistic or custom text analysis with Azure AI Search. Support for Lucene analyzers and Microsoft’s natural language processors is available, allowing you to configure analyzers for specialized processing of raw content, such as filtering out diacritics or recognizing and preserving patterns in strings.
For detailed information on specific functionalities, refer to the Features of Azure AI Search documentation.
Code Overview
All the code that relates to this post is in my public GitHub repository here: https://github.com/russellmccloy/azure-ai-search
- I used Terraform (You could use Bicep too if you like) to deploy most if the infrastructure for Azure AI Search. Unfortunately to deploy some of the Azure AI Search internal infrastructure such as Datasources, Indexes, Indexers and Skillsets I had to use direct REST API calls from Postman. The full Postman collection is included in the repository here Postman collection. To use the Postman collection you will need to edit the variables here: variables
To import a collection into Postman you can follow the instructions here: Import data into Postman
- I used documents supplied, plus 1 of my own that are mentioned in the Change Detection section below, by Microsoft here: Azure-Samples/azure-search-sample-data/tree/main/ai-enrichment-mixed-media. I have also included these in the supplied repository here.
After the Postman Collection has successfully run (I recommend running each step manually one at a time):
-
The indexer establishes a connection with Azure Blob Storage, fetching pre-loaded content. Subsequently, the indexer triggers a skillset for specialized processing, incorporating the enriched content into a search index.
-
The skillset is linked to an indexer and employs Microsoft’s built-in skills for information extraction. The pipeline encompasses Optical Character Recognition (OCR) for images, language detection, key phrase extraction, and entity recognition (organizations, locations, people). Newly generated information within the pipeline is stored in additional fields within an index. Once the index is populated, these fields become accessible for queries, facets, and filters. I used the following Skillsets:
Microsoft.Skills.Vision.OcrSkill- Extracts text (plain and structured) from image.Microsoft.Skills.Text.MergeSkill- Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.Microsoft.Skills.Text.SplitSkill- The Text Split skill breaks text into chunks of text. You can specify whether you want to break the text into sentences or into pages of a particular length. This skill is especially useful if there are maximum text length requirements in other skills downstream.Microsoft.Skills.Text.LanguageDetectionSkill- If you have multilingual content, adding a language code is useful for filtering.Microsoft.Skills.Text.KeyPhraseExtractionSkill- The Key Phrase Extraction skill evaluates unstructured text, and for each record, returns a list of key phrases. This skill uses the Key Phrase machine learning models provided by Azure AI Language.Microsoft.Skills.Text.V3.EntityRecognitionSkill- The Entity Recognition skill (v3) extracts entities of different types from text. These entities fall under 14 distinct categories, ranging from people and organizations to URLs and phone numbers. This skill uses the Named Entity Recognition machine learning models provided by Azure AI Language.- This skill can work on the following list of categories: “
- Person
- Location
- Organization
- Quantity
- DateTime
- URL
- personType
- Event
- Product
- Skill
- Address
- phoneNumber
- ipAddress
- If no category is provided, all types are returned.
- This skill can work on the following list of categories: “
Code Walk Through
Note: this post assumes knowledge of Terraform and working with REST APIs.
- Terraform: Run the Terraform to deploy the main resources. The
main.tffile is here main.tf
Note: I use a
dev.yamlconfiguration file to easily configure the Terraform here
resource "azurerm_resource_group" "this" {
name = "${local.prefix_name}-${local.config.resource_group.name}"
location = local.config.resource_group.location
}
resource "azurerm_search_service" "this" {
name = "${local.prefix_name}-${local.config.azurerm_search_service.name}"
resource_group_name = azurerm_resource_group.this.name
location = azurerm_resource_group.this.location
sku = local.config.azurerm_search_service.sku
}
resource "azurerm_storage_account" "this" {
name = "${local.prefix_name}${local.config.azurerm_storage_account.name}"
resource_group_name = azurerm_resource_group.this.name
location = azurerm_resource_group.this.location
account_tier = "Standard"
account_replication_type = "RAGRS"
}
resource "azurerm_storage_container" "this" {
name = "${local.prefix_name}-${local.config.azurerm_storage_container.name}"
storage_account_name = azurerm_storage_account.this.name
container_access_type = local.config.azurerm_storage_container.access_type # for the demo it's not private but it should be
}
-
Upload the documents to the storage account and container. Remember the documents are here
-
Use the Postman Collection (after updating the variables with your own as mention above. If you are new to Postman, you will need to import the collection into Postman. Note that the collection is fully self contained and doesn’t rely on environment variables.)
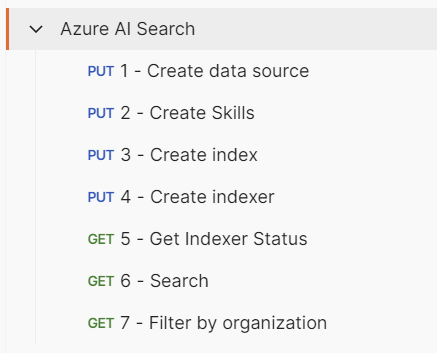
Note: You may need to wait a few moments before running the 4 - Create indexer step. When I ran in sequentially it failed. Not sure why.
- You can use the 5 - Get Indexer Status endpoint to see where the indexer is up to.
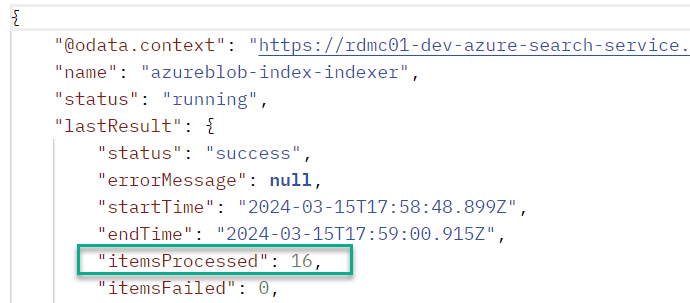
- Run the Postman endpoint called 6 - Search. If you search for
linuxyou should see the followingjsonresponse. If you look into the 2 images and the Word document, you will see that they mention Linux.
Find the
linuxsearch term in the following url:
https://{prefix_name}-{search_service}.search.windows.net/indexes/{index_name}/docs?search=linux&$select=metadata_storage_name,metadata_storage_path,language,organizations&$count=true&api-version=2020-06-30
{
"@odata.context": "https://rdmc01-dev-azure-search-service.search.windows.net/indexes('azureblob-index')/$metadata#docs(*)",
"@odata.count": 3,
"value": [
{
"@search.score": 9.235758,
"language": "English",
"organizations": [
"Microsoft",
"Open source",
"FEDORA",
"Centos",
"Linux Foundation"
],
"metadata_storage_path": "aHR0cHM6Ly9yZG1jMDFkZXZhenVyZXNlYXJjaHNhLmJsb2IuY29yZS53aW5kb3dzLm5ldC9yZG1jMDEtZGV2LWRvY3MvMTYuZG9jeA2",
"metadata_storage_name": "16.docx"
},
{
"@search.score": 7.8917985,
"language": "English",
"organizations": [],
"metadata_storage_path": "aHR0cHM6Ly9yZG1jMDFkZXZhenVyZXNlYXJjaHNhLmJsb2IuY29yZS53aW5kb3dzLm5ldC9yZG1jMDEtZGV2LWRvY3MvMTAucG5n0",
"metadata_storage_name": "10.png"
},
{
"@search.score": 7.8277144,
"language": "English",
"organizations": [],
"metadata_storage_path": "aHR0cHM6Ly9yZG1jMDFkZXZhenVyZXNlYXJjaHNhLmJsb2IuY29yZS53aW5kb3dzLm5ldC9yZG1jMDEtZGV2LWRvY3MvMTQuanBn0",
"metadata_storage_name": "14.jpg"
}
]
}
- If you are so inclined and want to see a proper front end consuming the data, run the MVCFrontEnd which is included in the repository here. However, if you can’t be bothered with a front end then just use the above mentioned 6 - Search in the Postman collection.
In the MVC front end app, remember to update the
appsettings.development.jsonfile with the following configuration values:
{
"AzureAISearchApiKey": "<SET_YOUR_SEARCH_SERVICE_API_KEY_HERE>",
"AzureAISearchService": "<SET_YOUR_SEARCH_SERVICE_NAME_HERE>",
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning"
}
}
}
Once you run it, you should see the following:
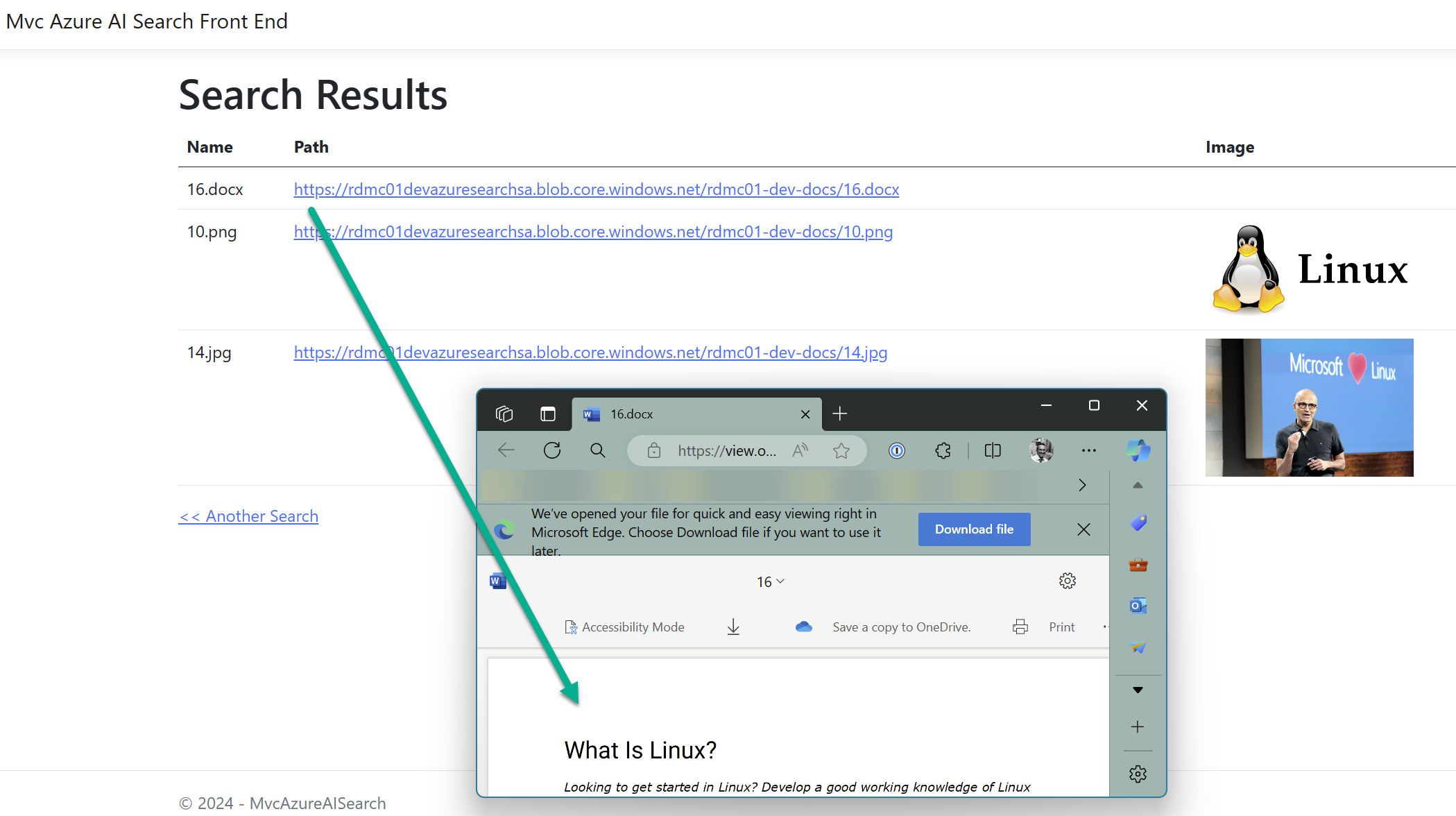
Change Detection
After an initial search index is created, you might want subsequent indexer jobs to only pick up new and changed documents. For indexed content that originates from Azure Storage, change detection occurs automatically because indexers keep track of the last update using the built-in timestamps on objects and files in Azure Storage. You can read about Change Detection here
After I added a new image, shown below, it was additionally shown in the search results:

Search Security
An Azure AI Search service is hosted on Azure and is typically accessed by client applications over public network connections. While that pattern is predominant, it’s not the only traffic pattern that you need to care about. Understanding all points of entry as well as outbound traffic is necessary background for securing your development and production environments.
Azure AI Search has three basic network traffic patterns:
- Inbound requests made by a client to the search service (the predominant pattern):
- At a minimum, all inbound requests must be authenticated using either of these options:
- Key-based authentication (default). Inbound requests provide a valid API key.
- Role-based access control. Microsoft Entra identities and role assignments on your Azure AI Search service authorize access.
- Additionally, you can add network security features to further restrict access to the endpoint. You can create either inbound rules in an IP firewall, or create private endpoints that fully shield your search service from the public internet.
- At a minimum, all inbound requests must be authenticated using either of these options:
- Outbound requests issued by the search service to other services on Azure and elsewhere:
- Outbound requests from a search service to other applications are typically made by indexers for text-based indexing, skills-based AI enrichment, and vectorization. Outbound requests include both read and write operations.
- Internal service-to-service requests over the secure Microsoft backbone network:
- Internal requests are secured and managed by Microsoft. You can’t configure or control these connections. If you’re locking down network access, no action on your part is required because internal traffic isn’t customer-configurable.
Internal traffic consists of:
- Service-to-service calls for tasks like authentication and authorization through Microsoft Entra ID, resource logging sent to Azure Monitor, and private endpoint connections that utilize Azure Private Link.
- Requests made to Azure AI services APIs for built-in skills.
- Requests made to the machine learning models that support semantic ranking.
Why is Azure AI Search so good?
In my opinion Azure AI Search is a great search solution. I think the main reason is, is that it does all the heavy lifting for you:
- All you need to do is upload your documents to single or multiple data sources
- As Azure AI Search is an intermediary positioned between external data stores housing your un-indexed data and the client app responsible for sending query requests all you need to do is build a client app to call the Azure AI Search service and display the search results.
- It’s totally scaleable for any size organisation
- It’s designed to allow the security you expect in Azure Cloud
Issues I encountered
- Regarding the resources inside the main Azure AI Search resource (Indexes, Indexers, Data Sources and SkillSets), it seems I can’t only deploy these via the Azure AI Search REST API (you can create these using the Azure AI search SDKs. Here is the .NET SDK. I looked at deploying these with Terraform and then ARM templates (and Bicep) but it looks like it’s not possible.
- Regarding the
metadata_storage_pathwhich, in this case is the URL that points to the blob in my storage container. No matter what I tried, after decoding the base64 string, I could not get a reliable URL to point to a blob in my search results (occasionally there was an extra zero added to the end of themetadata_storage_pathfield). This means my MVC front end is a bit hacked but as it is not the focus of this proof of concept, I ran out of time to make it work seamlessly. If you look at the 4 - Create Indexer inside the Postman Collection you will see the following:
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" } < ========== 😁
},
...
],
Useful Links and Documentation I Used
- The main documentation for Azure AI Search
- Tutorial: Use REST and AI to generate searchable content from Azure blobs
- AI enrichment in Azure AI Search
- Security overview for Azure AI Search 🔒